
听到 DeepMind CEO 聊中国 AI,有一句话尽头逆耳:中国 AI 毫无更变,只不外是跟进速率可怕。
这话,听着是不是很熟悉?
前两年叙事里,这果然成了西方对咱们的想维定势,他们负责「从 0 到 1」的发明,咱们负责「从 1 到 100」的内卷。
哪怕咱们跑得再快,在他们眼里,充其量也即是个「劳作的侍从者」。
说真话,这种论调昔日咱们很难反驳。因为你掀开任何一个海外主流榜单,放眼望去,清一色的好意思国居品;比如:OpenAI、Google、Anthropic。但偏见这东西,最怕硬数据。
今天(12 月 23 日),全球公认最难刷榜、最崇拜「盲测体验」的大模子竞技场 LMArena ,更新了排行;在宽阔好意思国模子的重重包围里,百度文心 ERNIE-5.0-Preview-1203 杀了出来,以 1451 分拿下了国内第一。
这个分数意味着什么?
海外舞台上,文心已成为国产 AI 的优秀代表,在 LMArena 排行前 10,朝上了 Claude Sonnet4.5、GPT-5.2 等前沿模子,是前 20 里独一的非好意思国模子,冲破了好意思国驾驭。
当独一的中国名字出现时榜单前方,当咱们的 AI 依然不再得志于「跟跑」时,中好意思 AI 的这盘棋,逻辑是不是依然变了?
智远分析认为,跑赢这事儿,不行光靠气运,也不行全靠「堆显卡」,我成心翻了一下文心 5.0 Preview 背后的技艺文档,发现百度在练几门很狡滑的「内功」,这亦然它能解围的中枢原因。
第一,最中枢底座是一个「原生」的生命体。
注意这个词:原生全模态(Native Omni-modal);以前许多所谓「多模态」模子是「对付」出来的,给大模子外挂一个看图的眼睛、外挂一个听声息的耳朵。
这种后期和会诚然能用,但各感官之间是割裂的;文心 5.0 不不异。它袭取了「原生全模态长入建模」技艺。
打个比喻:
它像一个天生具备视、听、说智商的生命体;从教师的第一天起,文本、图像、音频、视频即是和会在一王人学习的。
是以,它能平直解析视频里的心境,平直看懂图片里的逻辑,这种"出厂建造"级别的互异,让它的解析和生成智商,平直上了一个台阶。
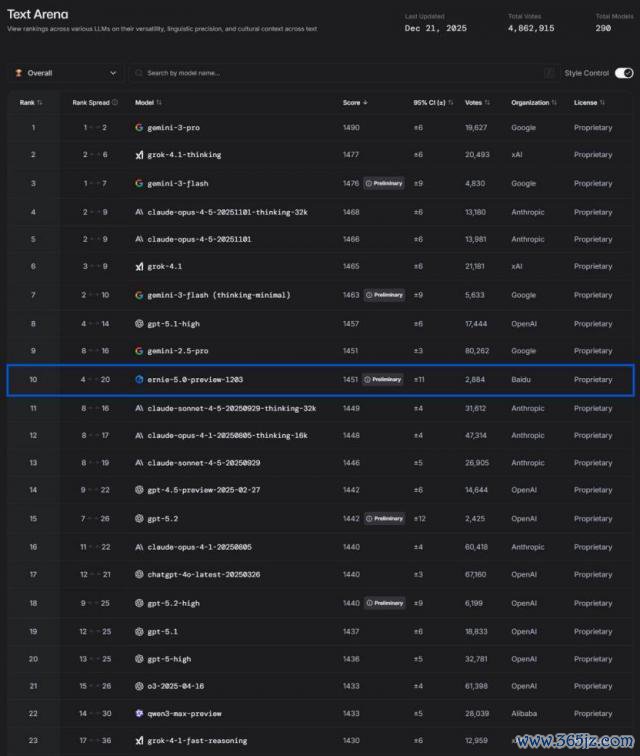
图释:LMArena 最新榜单,文心 5.0 Preview 以 1451 分杀入全球前十,稀疏 GPT-5.2,成为前 20 名中独一的非好意思国模子 。
第二招,是「大块头」也有「大颖慧」。
文心 5.0 参数目达到了惊东说念主的 2.4 万亿。这是现时业界已公开参数模子里的「巨无霸」。
不绝咱们认为,模子越大越清苦、越烧钱;百度用了一种「超大规模搀和大家模子(MoE)架构」,解决了个悖论。
肤浅说,这 2.4 万亿参数像一个雄壮的大家库,在处理具体问题时,只激活其中不到 3% 的关系大家来干活;在 LMArena 这种拼响应、拼逻辑的盲测里,这种架构上风相配昭彰。
第三招,是「想考」与「看成」的合体。
文心 4.5 启动就悉力于于「知行合一」,突破了仅基于想维链优化的范式,在想考旅途中蚁集用具调用,构建了和会想考和看成的复合想维链,模子解决问题智商获取权贵栽植。
同期,蚁集多元长入的奖励机制,结束了长距离想维和看成链的端到端优化,权贵栽植了跨领域问题解决智商。
是以,不行把它肤浅归纳为弯说念超车。
从「拼接」走向「原生」,从「堆参数」走向「MoE」,从「单点问答」走向「智能体想考」,这 1451 分的背后,是技艺道路的质变。
当不再盲目堆算力,启动在架构、想考智商上找突破口时,打赢 GPT-5.2,也就不是什么不可想议的事了。
不可想议,不是我残害能说了算。毕竟,刷榜这事儿,中国不爱干,干了也没用,能把技艺用到应用中,才是真身手。
DeepMind 以为中国 AI 零落更变,原理是咱们太热衷于「应用」,但智眺望来,这恰正是中西方视角的错位。
硅谷更变时时在履行室的白板上,追求算法"从 0 到 1 ";而中国更变,长在土壤里,长在车间里,长在代码行里,追求产业的"从 1 到 100 "。
我认为,反驳「无更变论」最有劲的兵器,是看能不行解决好意思国 AI 根底没遭受过、甚而遐想不到的复杂难题。比如说:在大国重器里,解决「物理宇宙」的硬伤。
来望望文心大模子在百行万企的应用:
中车集团传奇过吗?造高铁的阿谁。以前作念高铁的气动外形商量,那是纯物理活儿,更是个「苦力活」。
因为空气看不见摸不着的,商量师商量一个车头,好不好用,必须得扔进风洞履行室里吹。
跑一次数据,波及海量的流膂力学计较,可能要耗时好几个月,况兼风洞履行的老本极高,不错说是"烧钱又烧时分"。
现时呢?一切变了。
他们把文心大模子用在了空气能源学仿真上。基于百度飞桨的科学计较智商,大模子学习了海量的历史履行数据,它依然「懂」了风的法例。
有了这个「外挂」,昔日几个月的履行周期,现时最快几分钟就能算出末端。商量师有一个新看法,坐窝就能跑出数据考据,更变的迭代速率快了成百上千倍。
更科幻的是,他们还搞了个「诬捏传感器」。
这又是什么黑科技呢?这样说吧,高铁上有许多精密部件没法装置实体传感器的(比如空间太小,或者环境太恶劣)。
以前这些地方出了问题,只可靠猜或者靠熟习。但现时,诈欺大模子坚毅的推演智商,能凭现存的电流、电压等外围数据,AI 就能在诬捏宇宙里"推算"出中枢部件的及时景色。
这好比给列车装了一对透视的"天眼",把故障检测的准确率硬生生在现存传感器检测的基础上再栽植了 10%;这 10%,关乎中国高铁的安全,关乎的是亿万乘客的生命。
再比如:国度电网。以前巡检电塔,那是工东说念主拿命去爬,风吹日晒。现时靠无东说念主机 + 大模子,一年巡检 500 万基杆塔,东说念主工登塔次数平直减少了 40% 。
这种把 AI 塞进高铁和电网里,解决物理宇宙硬伤的智商,DeepMind 见过吗?
若是说工业是「硬度」,那代码即是「速率」;咱们都知说念 AI 能写代码,但能不行进中枢业务流?顺丰科技给了一个很吓东说念主的谜底 。
大众可能不知说念顺丰的业务系统有多复杂。它不仅有物流舆图,还有运单流转、仓储治理 ......
这些系统里,千里淀海量的、只消顺丰东说念主懂的「专有常识」。通俗通用大模子,你问它"怎么优化运单路由",它只可给你讲一堆正确的鬼话。
但顺丰用的文心快码(Baidu Comate),走了一条不同的路。
它通过 RAG(检索增强生成) 技艺,像外挂硬盘不异,无缝接入了顺丰里面雄壮的私域代码库和文档库;当重要员敲下一转代码时,AI 无须瞎猜了。
平直在顺丰千里淀了十几年的技艺财富里短暂检索,找到最匹配的逻辑,生成代码。效果何如样呢?现时顺丰全公司,日均 20% 的代码是由 AI 生成的 。
畸形于每五个字代码里,就有一个是 AI 写的。目田了顺丰 1000 多名设备者的分娩力,让他们从无聊的「搬砖」中开脱出来,去想考更复杂的物流算法 ;这是实打实的新质分娩力。不炫技,在给企业省钱、增效。
智远再说一个应用场景最稀缺的例子:社会治理。
在好意思国,AI 处理圭臬英语也许很容易。但在中国,处理老匹夫夹杂着方言、心境振奋、逻辑芜杂的投诉,是对 AI 解析力的极致考验。
北京市海淀区的「接诉即办」系统,每月受理量十几万,以前靠东说念主工听灌音、打标签,根底搞不外来。
因为数据量太大了,况兼曲直结构化的。现时接入文心大模子后,它不仅能更懂东说念主性,还能从一堆叨唠里精确索要诉求,自动分类填单 。
数据反差极其锐利:
以前作念肤浅地点统计要 3 天,现时只消 1 分钟;画个图表以前要 5 天,现时 30 分钟处置;这是给雄壮的城市治理装上了一个及时想考的"大脑",让治理者能听懂每一句东说念主间焰火。
终末,若吵嘴要说咱们不懂基础科学,那就去上海交大望望。
传统科学履行,其实很笨。就像爱迪生试灯丝不异,要在履行室里进行车载斗量次的访佛试错,耗时耗力 。
上海交大基于文心大模子搞了个 AI for Science 平台 。现时,只消输入分子 SMILES 序列,5 秒钟之内就能检索出响应流程、响应要求和关系文件 。
这个后果,平直登上了 Nature Computational Science 的封面 。
Nature Computational Science 是什么?不懂行的认为这仅仅一篇论文,但在学术圈,这本《当然》旗下的顶级子刊,代表着「计较 + 科学」交叉领域的最高门槛。
能上封面,意味着中国 AI 除了作念应用,还能界说基础科学的畴昔范式。
是以,当看到 AI 启动教悔化学响应,启动商量高铁外形,启入耳懂老匹夫方言,启动替重要员写两成的代码时,还会以为中国事侍从者吗?
终末,智远想说一个细想极恐的细节。保重 LMArena 的一又友会知说念,哪怕你看到了它排在国内第一、全球前十,别忘了,它的名字后缀里还挂着一个词:Preview(预览版)。
什么道理?
也就说,击败 GPT-5.2、把不少好意思国模子甩在死后的「文心 5.0」,如故一个「未全都体」;这就像武林能手过招,对方还没拔剑,仅仅试探性地出了一掌。
智眺望到榜单后,问了下熟悉的东说念主,他们说:文心大模子 5.0 郑再版,冒失率会在 1 月份肃肃上线。
试想一下,一个 Preview 版块依然能在竞技场里撕开铁幕,那经过一个月打磨后的郑再版,又会拿出什么样的性能呢?
若是只盯着分数,可能又看走眼了,因为现时大模子上榜大众保重少了,智远以为,这事儿还有更深的一层意味。咱们不仅要问文心 5.0 还能得若干分,更要问一个终极问题:
当技艺代差被抹平之后,中好意思 AI 的终局竞争到底拼什么?拼谁的模子多 10 分?如故拼谁的参数大一倍? 都不是。
拼谁能把技艺酿成像水和电不异,流进每一个通俗东说念主的生存里。
这亦然智远认为,百度在模子高下功夫的地方;它不仅我方在进化,它还带着通盘这个词生态在进化;以后要把它用到 AI 搜索里、百度文库网盘里、以及企业作事场景里,岂不是成了降本提效的「日用品」?
是以,当 DeepMind 还在哄笑咱们「应用快」的时候,他们可能没意志到:应用,本人即是一种巨大的技艺壁垒。
因为应用会产生数据,数据会反哺模子,模子进化了又带来更好的应用;这是一个正向出动的雪球。 而文心模子,是在雪球的中心。
是以,回到 DeepMind 那句无礼的评判。
当中国名字出现时榜单前方,当咱们的 AI 深远到高铁与政务的毛细血管,当"预览版"能同台竞技时,非论硅谷如故 DeepMind,偶而都该换一副眼镜看中国 AI 了。
承认别东说念主的优秀,并不丢东说念主。
在这个时间,更变莫得时分末端,莫得驾驭权;它不错发生在加州的履行室里,也不错发生在中国的高铁车间里。
中好意思 AI 的故事,是「双强并峙,各登山顶」。这,才是 AI 赛场上的真相。我也相比期待啥时候上线郑再版。
